从接触推荐系统以来,断断续续的已经有一年半的时间了。 今天想单纯从工程角度来总结一下我得到的经验,不涉及推荐的数学算法和理论。 第一是公司还没有到必须扩展现有的推荐算法的地步,第二是本人自知没有足够能力来改进现有的推荐算法。
其实主要是因为第二点。
总体回顾
在介绍可扩展的推荐平台我是如何设计之前,还是稍微回顾一下公司推荐的发展历程,因为这可能具有一定的代表性。或许在开展新的推荐研究时有一定参考价值。
诺基亚
我开始做推荐之前一直是我们数据部门的同学来做的,当时是使用 SQL 查询来实现了推荐的相关算法。想必这也是不得已而为之吧,最起码说明算法理论很熟悉:P。 调整一些参数或是新增推荐显然很痛苦。
但有总比没有强,在 iPhone 出现之前,诺基亚一直已智能手机自居。人们的感觉是跟智能有点关系,但总觉得怪怪的。这也是当时我们公司使用推荐的感觉。
Romar
在开始做新的推荐引擎之后,我们的思路就是找一个开源实现。很快就锁定了 Mahout,原因有以下几点:
- Apache 基金,项目的更新和质量有保证
- 实现了大多数已知的推荐算法,同时考虑了机器学习的其他两个分支:聚类和分类
- 分布式计算,为大数据而设计
但 Mahout 只是一个类库,我一直喜欢拿 Solr 和 Lucence 的关系来类比。 Mahout 类似 Lucence 是一个底层类库,并不是上层应用和产品。 于此同时,Mahout 版本的 ‘Solr’ 还没有出现,有几款开源实现但并不理想,也不是 Apache 官方的作品。
所以我们决定自己简单的在 Mahout 上面薄薄的搭一层 API 来提供服务,起了个名字叫 Romar。很快这个目的就实现了,项目可以在 GitHub 上找到。
Romar 1.0 的版本应该足以应付千万级别用户行为的协同过滤计算,所以很快在公司内部得到了快速应用。 得益于其能够快速响应业务需求的特点,短短半年内覆盖了公司所有产品线,这也算技术推动产品的经典案例了。
但问题随之而来。
管理这些推荐引擎变得痛苦,越来越多的实例。它们的管理成了最大的问题,包括部署、监控、可靠性、平滑升级。
备选方案
很显然需要一个平台来管理这些实例,同时推荐引擎本身也需要一些升级。
- 平台来管理、部署实例及其配置
- 平台来查看实例服务的状态
- 推荐引擎为以后准备,支持海量数据的离线计算
与刚开始时类似,我们也找了几个开源实现,其实和我们思路类似,都是基于 Mahout 的一些产品,这里稍作介绍。
PredictionIO vs Oryx
PredictionIO 是一个大而全的产品。说到「大而全」,已经概括了我对这个产品的看法。
- 主打 Cloud 业务,即部署在他们的云端。这是主要的盈利方式。只是顺便开源了代码,可以自己搭建。
- 但自己搭建并没有很好的脚手架或是文档,开源的安装脚本落后且复杂,一旦出错需要从头开始。
- 配置太多,把更多的选择留给用户,看似是自由度很高,反过来看就是复杂。
- 唯一可取的是界面样式设计很有科技感。
所以 PredictionIO 还没到真实数据测试阶段就已经被放弃了。
Oryx 的前身叫 Myrrix,后来被 Cloudera 收购改了这个名字。值得一提的是 Oryx 的维护者就是 Mahout 的主要贡献者。
严格来讲 Oryx 并不是我要找的「平台」,但我们考虑用来直接代替 Romar 来作为后端引擎。
Oryx 具有以下特点:
- Hadoop 版本跟着 CDH 升级
- 将推荐引擎分为 Serving Layer 和 Computing Layer,隔离出 Serving Layer 让扩展变得很容易
- 同时支持推荐、聚类、分类的机器学习
- 数据引入了 Generation 的概念,提供了很好的增量补充数据的支持
看起来很美好,试用之后发现了一些问题,其中的大多数都与作者做了深入的沟通,总结起来可能有以下几点:
- 没有额外的组件,意味着没有额外的存储空间。Serving Layer 内存有瓶颈。
- 只支持了一种协同过滤算法,即 ALS (alternating least squares) 。这种算法精度更高,但计算时间长,且中间结果无法缓存,Serving Layer 在不到百兆数据级别就会响应很慢。 具体可以看这个 issue。
基于以上 2 点,我们还是最终没有把 Oryx 应用到生产中。
The answer
我们总是讨厌重复造轮子,但如果能基于现有方案造出更好的轮子,也不失为一种选择。
融合了 PredictionIO 与 Oryx 的优点,我认为一个用户友好的、可扩展的、成熟的推荐系统应该具备以下特点:
- 方便部署。应该使用一些 CM(Configure Management) 工具,或者配合 Docker、Vagrant 等虚拟环境来快速的搭建统一的环境。
- 支持多种算法,有些场景简单的余弦相似度已经满足需求。
- Serving Layer 要与 Computing Layer 解耦。
- 增加 key-value 缓存层,释放 Serving Layer 的内存压力。
- 平台界面操作简单,尽可能的对用户隐藏后端引擎的细节。
- 推荐引擎对客户端透明,这个比较难理解,后面单独说明。
设想中的架构应该类似于这样:
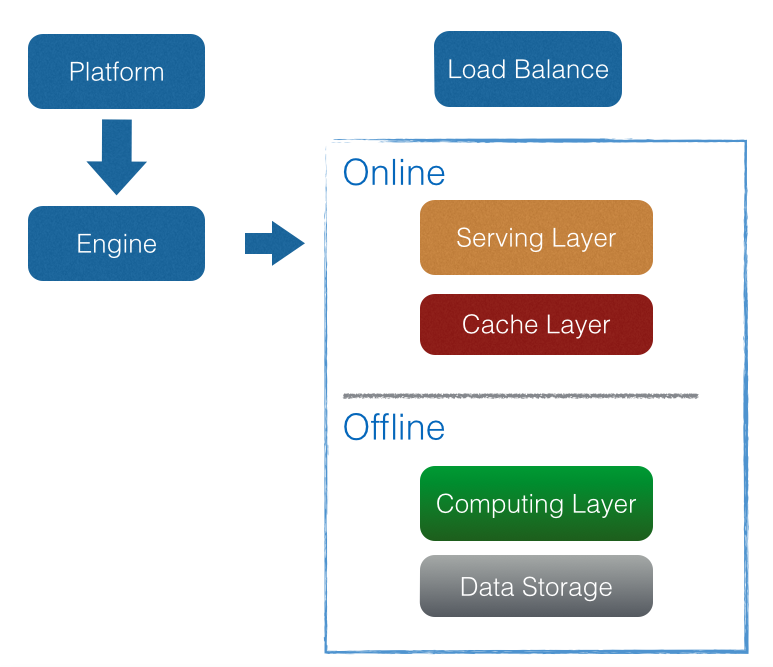
Platform
从平台的逻辑角度来说,可以将推荐引擎分为两层: App 和 Instance。
一个 App 字面上理解就是一个推荐应用,应该包括了使用的数据和引擎的配置。 一个 App 可以有多个 Instance 同时进行服务,各个 Instance 使用 App 的数据和配置。
创建新的推荐应用不需要关心背后使用的引擎、版本,以及部署在哪台机器、哪个端口(但在创建完成后可以查看)。
Serving Layer
仅从 Cache 中获取结果返回给客户端。同时保留将来一定的扩展性,比如没有读到数据可以发指令给 Computing Layer 重新计算。
Computing Layer
同时支持离线集群计算和单机计算。当单机计算时,计算结果直接存入 Cache;当离线计算时,将结果从集群中读出后转存至 Cache。
Data Storage
如何获取和存储用户行为是另外一个很大的课题,不在这里展开。这里我们假设可以方便的拿到所有用户行为。
CRGI
受到 CGI(Common Gateway Interface) 的启发,我认为只要规定好输入输出,推荐的客户端可以无视后端引擎。 而后端引擎可以只要满足输入输出,便可以随意更换实现。
即 CRGI(Common Recommendation Gateway Interface),CRGI 是一份协议或声明,凡是满足协议中描述的输入输出,理论上都可以作为这套系统的推荐引擎。
由于这里 Serving Layer 由我们自己控制,所以一定是满足 CRGI 协议。如果后端更换了第三方引擎,则需要 Proxy 来适配。
Load Balance
在所有 Serving Layer 的 HTTP Server 之前加一层 LB。 这样可以进一步简化客户端调用,不需要知道 IP 地址和端口号。同时可以在 LB 上统一的管理所有 APP 的访问日志。
Logs and Monitor
访问日志由 LB 统一管理,Error Log 则由各 App 自己管理。可以使用第三方工具来监控 Error Log 并依据访问日志来绘图。 最终展示在 Platform 上。
Engine Upgrade
- 所有 App 使用同一版本引擎
- 如果更换引擎则所有 App 需要同时更换
- 如果引擎升级,则视为一次更换
避免了 App 间的版本差异,会给管理带来很多好处。只是需要制定详尽的在线升级策略。
做到了以上几点应该可以构建出非常强大而灵活的推荐系统。